プロポーザルの書き方
最後にCfCAを初めとする大型計算機センターの計算機を利用するために、プロポーザルあるいは研究計画書の書き方について説明します。多くの場合プロポーザルは研究目的や期待される成果の説明と、それに必要な計算機資源の見積もりの2つが要求されます。ここで説明する内容はCfCAの計算機に限らず一般的なものです。
研究目的
研究目的についてはここでは当然ですが個別の説明はできません。しかし一般論として、研究目的の重要性を正当化することはもちろん重要ですが、それに加えて具体的にその分野で何がわかっていて何が謎として残っているのか、そして当該期間でどこまで明らかにすることを目指すつもりなのかを明記しましょう。そしてそのシミュレーションが目的のために妥当な設定であること、また現実的な時間で目的が達成できるということを明確に正当化する必要があります。また、気をつけるべき点として(これは学振などの書類でも同様ですが)審査員は必ずしもあなたの分野の知識があるわけではない、というよりもない可能性の方が高いです。なので基本的なバックグラウンドから既知のこと(適切に先行研究の文献を引用して下さい)と未知のことを明確に分けて簡潔に説明することを心がけて下さい。また許可されているならば必要に応じて図を使うのも効果的です。以下に私が過去に書いた申請書の抜粋を載せておきますので参考にして下さい。
研究の意義・目的
星の初期質量分布関数(IMF)を第一原理的に導出することは星形成研究の究極の目標である。IMFが多くの星形成領域でよく似た分布をしている(e.g. Chabrier et al. 2003)事実はIMFの起源が何らかの普遍的な物理過程によることを示唆する。観測的には個々の星形成過程の初期条件に対応する分子雲コアの質量分布関数(CMF)がIMFとよく似ており(e.g. Enoch et al. 2008, Andre et al. 2010他)、素朴には各分子雲コア質量の一定の割合(星形成効率)が星に転換されると解釈することができる。しかしこのような単純な1:1対応が実現しているかは自明ではなく、星形成効率の決定機構も十分には理解されていない。これまでの研究で低質量星では磁場によって駆動されるアウトフローが最終的な星質量を制限する可能性が指摘されており、大質量星では強力な輻射によって質量が制限されると考えられている。一方、これらのフィードバックの強さは大スケールの分子雲から継承された初期条件、即ち母体分子雲コアの質量や磁場、回転等に依存しているため、これらのパラメータの分布を第一原理的かつ統計的に明らかにする必要がある。このような分子雲から分子雲コアまで一貫したシミュレーションには磁気流体力学、輻射冷却、自己重力、化学反応等多様な物理過程と、分子雲コアの内部構造を分解する高い分解能が必要である。我々はこれらをすべて満たすAthena++コードを用いてこのような研究に取り組んできた(e.g. Iwasaki et al. 2019)。
前年度までの研究では、衝突するガス流中で形成される分子雲コアの質量分布関数や磁場強度の分布を調べてきた。特に、分子雲コアの持つ磁場の強さの指標となる質量-磁束比(mass-to-flux ratio μ)が、分子雲コアの質量の1/3乗に比例するという関係に従う(図省略)ことを見出した。この結果から、分子雲コアは形成初期には磁場が支配的であるが、質量を獲得して成長するに従って重力が支配的となって星形成を起こすという描像が明らかになり、Zeeman効果の質量-磁束比の観測(e.g. Crutcher 2012)とも整合的な結果である。本研究成果をまとめて現在論文を執筆中である。 今年度はこれまでの研究に引き続き、パラメータ空間を広げると共に磁場の進化に重要となる両極性拡散を取り入れた計算を行い、分子雲コアの質量や回転、磁場の分布等の統計的性質を調べ、現実的な星形成研究の初期条件を明らかにする。これらは電波望遠鏡により観測可能であり、理論シミュレーションと観測を直接比較する上でも重要である。本研究の結果をもとに磁場によるダスト連続波の偏光の輻射輸送計算を行い、Planck衛星やJCMT(BISTRO)の分子雲スケールの磁場の観測と直接比較するsynthetic observationの研究も平行して進めている。そのため本研究は分子雲スケールの星形成と磁場の理解に理論と観測の両面から貢献するできる。
本研究で使用するAthena++コードはPrinceton高等研究所を中心とする国際協力で開発している公開コードであり、申請者は開発の中心的役割を果たしている。本研究で開発したコードもAthena++プロジェクトの一部として公開する予定である。
研究計画・方法
本研究では申請者がPrinceton大学のグループと共同で開発しているAthena++コードを用いる。このコードは磁気流体力学、両極性拡散、輻射冷却、自己重力、化学反応等本研究に必要な物理過程を全て含んでおり、また自己重力部・磁気流体部共に高い性能が得られている。
個々の星形成過程の初期条件となる分子雲コアの典型的な大きさは0.1pc程度であり、その内部構造まで正確に分解するには少なくとも0.02pc以下の分解能が必要となる。我々は分子雲コアの形成過程と構造を可能な限り第一原理的に明らかにするため、高分解能磁気流体シミュレーションに取り組んでいる。本研究では超新星爆発からの衝撃波による圧縮過程のモデルとして磁場を持つ二層星間物質を衝突させ、衝撃波圧縮で熱的不安定性を引き起こすことで高密度分子雲の形成と乱流の駆動をモデル化する。典型的な分子雲スケールである10pcをカバーする40pc x 20pc x 20pcの計算領域を使用し、これを0.02pc以下の高分解能で計算する。Athena++はAdaptive Mesh Refinementに対応しているが、形成される分子雲は広い体積に渡って乱流状態になるため、AMRよりも大規模な一様格子で計算した方が計算効率上優位となる。そのため本研究では一様格子を用いる。この計算によって得られた高密度分子雲コアを観測と同様の手法を用いて同定し、それぞれの質量・回転・磁場などの情報を統計的に調べることで、分子雲コアの性質と母体分子雲との関係を明らかにする。
前年度までの研究で衝突ガス流中での分子雲形成過程の自己重力入り高解像度磁気流体シミュレーションを行い、個々の星形成過程の初期条件となる分子雲コアの形成過程について調べた(図省略)。その結果分子雲コアの質量・回転・乱流エネルギー・磁場強度などが統計的に明らかになり、観測されている分子雲コアの性質を概ね説明できる結果が得られている。一方で、分子雲は電離度が低いため非理想磁気流体効果、特に中性粒子と荷電粒子がデカップルすることによる両極性拡散が働き、磁場の拡散や摩擦加熱によって分子雲コアの構造に影響する可能性がある。これまでの計算は理想磁気流体近似で行ってきたが、ポストプロセスで典型的な電離度を仮定して両極性拡散の時間スケールを見積もった所、分子雲形成の時間スケール(数Myr)よりも短い時間で両極性拡散が働くことが分かった(図省略)。そこで今年度は、両極性拡散を取り入れた新たなシミュレーションを行い、より現実的な分子雲コアの性質を明らかにする。
コードの性能・スケーラビリティの測定
大型計算機の利用、特に大規模な計算を行うために大量の計算機資源を要求する場合はコードが十分に高い性能が達成できることを証明する必要があります。特に最近の大規模並列計算機では並列数を増やしても性能が落ちないこと、即ちコードが良好なスケーラビリティを持つことを示す必要があります。Athena++はXC50で1ノードあたり40プロセス、1プロセスあたり643セルで計算した場合、2次精度のHLLC法を用いた流体計算であれば2.1x106cells/sec/core程度、HLLD法による磁気流体計算であれば1.1x106cells/sec/core程度の性能が期待できます。追加の物理過程がないのにも関わらずこれらの数値を大幅に下回るようであれば、コードや設定に何らかの問題がある可能性を示唆します。詳細はAthena++コードの論文(Stone et al. 2020)を参照してください。
次にスケーラビリティの測定法について説明します。スケーラビリティの測定には、1プロセスあたりの計算量を固定して(=全計算量をプロセス数に比例するようにして)プロセス数を増やして性能を測定するウィークスケーリングと、問題のサイズを固定して(=1プロセス当たりの計算量がプロセス数に反比例するようにして)性能を測定するストロングスケーリングの二種類があります。たいていの場合どちらか片方を測定することが要求されますが、いずれの場合でも実際の計算を反映し、同等の計算量となるような状況設定で測定するようにしてください。
まずウィークスケーリングの測定方法について説明します。まず実際に計算に使用する計算量を想定して1プロセス当たりの計算サイズを決めます。仮に1プロセス当たり643用いることに固定して、そしてコア数を2倍、4倍・・・と増やしていきます。XC50は1ノード当たり40コアあるので、40コアを基準として測定するのが良いでしょう。ここでの設定はあくまで例なので、実際に使う計算に合わせて測定して下さい。
| ノード数 | プロセス数 | MeshBlock数 | セル数 |
|---|---|---|---|
| 1 | 40 | 5x4x2 | 320x256x128 |
| 2 | 80 | 5x4x4 | 320x256x256 |
| 4 | 160 | 8x5x4 | 512x320x256 |
| 8 | 320 | 8x8x5 | 512x512x320 |
| ... | ... | ... | ... |
| 64 | 2560 | 16x16x10 | 1024x1024x640 |
この測定を行う際はパラメータファイルの<meshblock>を固定して、Meshのサイズを変更します。またoutputは全てオフにして、短時間(10分程度または1000ステップ程度)の計算を行います。Athena++は計算が正常に終了した時に性能を表す数値(ログファイルの最後に表示される"zone-cycles/cpu_second"の値)を出力するので、これを並列数で割って1コア当たりの性能を測定します。実際にXC50でAthena++の性能を測定した例を以下に示します。このような図を作成してプロポーザルに載せることをお勧めします。例えば40コアの計算に対して2560コアの計算の数値が97%であれば、97%の性能でウィークスケーリングする、ということができます。単純な流体計算のウィークスケーリングであれば、これは90%以上を維持するべき値で、50%を切るような設定では計算資源の無駄遣いになるためそのような計算をしてはいけません。(ちなみに2ノード以上の計算ではネットワークをまたぐことになるため1ノードから多少の性能低下が発生します。また1コアから40コアまでの1ノードに収まる範囲では1コア当たりのメモリバンド幅が減っていくため、性能が低下するのは自然であり必然です。)
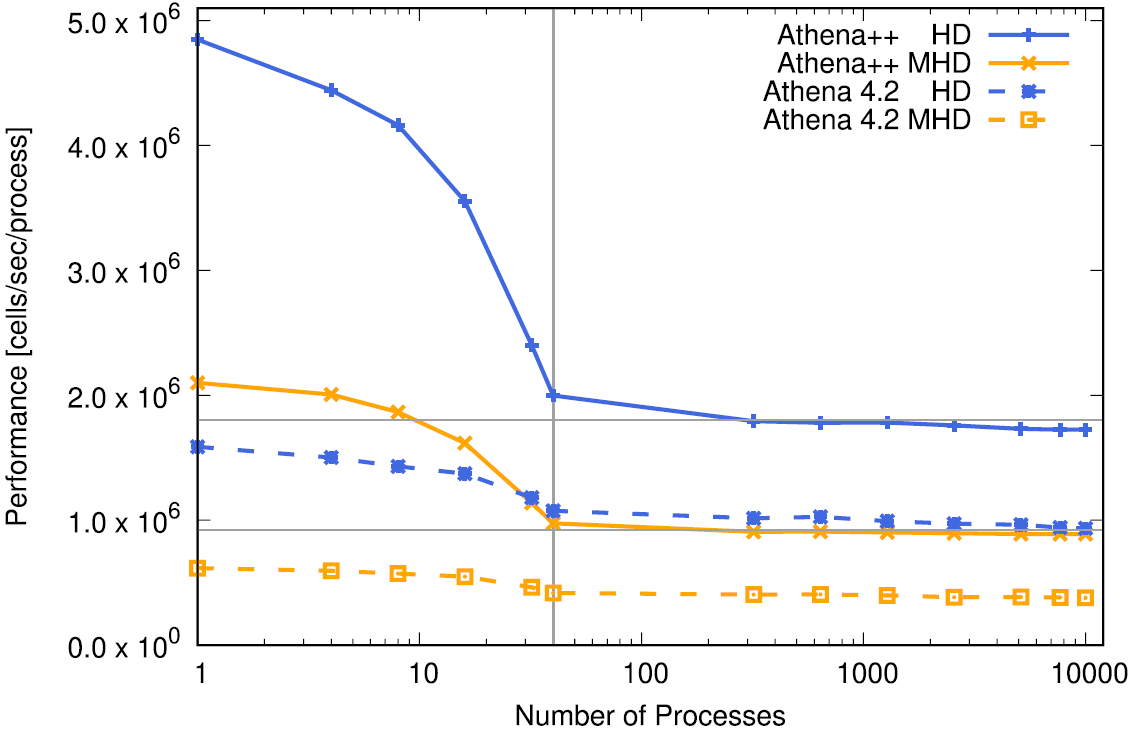
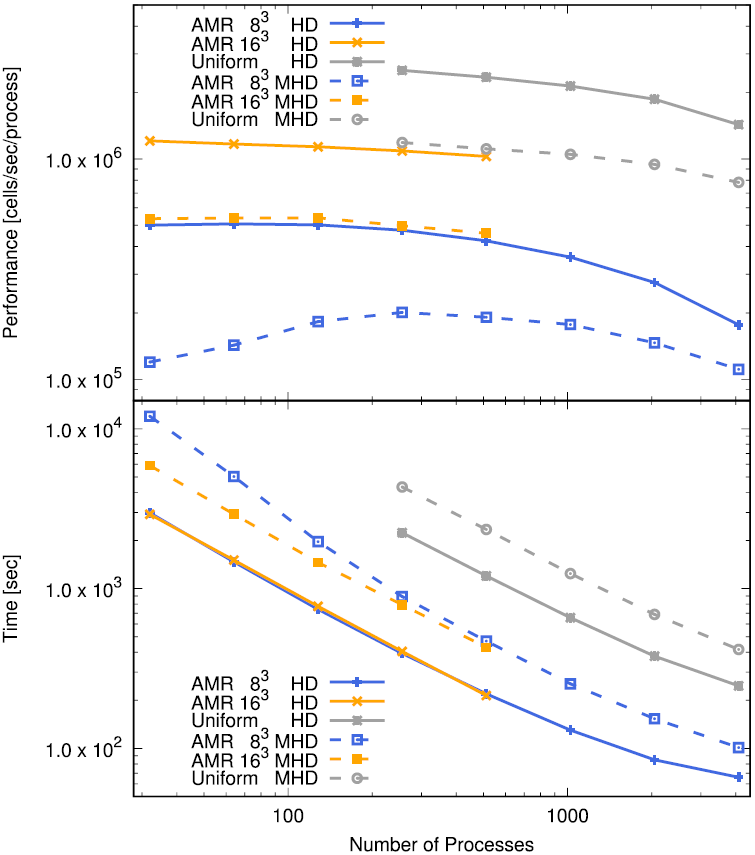
一方、ストロングスケーリングでは問題全体のサイズを固定したまま、プロセス数を増やして性能を測定します。理想的にはプロセス数を2倍にすれば計算時間が半分になって欲しい所ですが、実際にはシミュレーションにはプロセス間の通信などプロセス数を増やしても計算時間がそれに反比例して減らない部分が必ず存在します。そのため、ストロングスケーリングではプロセス数を増やすと理想的な性能(両対数グラフで傾き-1の直線)からずれてきます。このずれがどれくらいのプロセス数で顕著になるかを調べ、それ以下のプロセス数でシミュレーションを実行するのが理想的です。ストロングスケールの性能は当然設定する問題サイズに依存しますから、ベンチマークとしてストロングスケーリングを示す場合は本計算でターゲットとする問題と同程度の問題サイズを設定する必要があります。ノード数が少ないとメモリ不足や計算時間がかかり過ぎるなどの理由でテストできないこともあるので、問題サイズに合わせて適切な範囲で測定しましょう。ストロングスケーリング性能のテスト結果をもとに実際の計算で使用する計算設定(プロセス数、分解能など)を決定するのに役立ちます。以下にAthena++のAMRを利用したblast wave testのストロングスケーリングの結果を示します。
計算コストに加えて、必要メモリ量についての見積もりを求められる場合がありますので必要に応じて記入します。格子法の流体計算ではメモリ量が問題を制限することはほとんどありません。例えば1プロセス当たり643セルの磁気流体計算の場合、流体変数5(質量・運動量・エネルギー)x2(conservative variablesとprimitive variables)と磁場変数3x2(セル表面とセル中心)の合計16変数がサブステップ毎に1セット、二次精度の時間積分法であれば32変数必要になります。それに加えて各方向への数値流束が各サブステップで保持されているので、3x8=24変数あります。また袖領域が2次精度の場合各方向について2x2セルあるので、合計で必要な変数は倍精度ならば(32+24)x(64+4)3x8Bytes=141MBytes程度になります。更に少量の一時変数が必要ですが、これを多めに2倍強程度と見積もったとしても300MBytes程度であり、XC50であれば全く問題になりません。XC50は比較的メモリに余裕のある計算機ですが、コア当たりのメモリ容量はどちらかといえば減少傾向にあり、富岳に搭載されたA64fxのようにメモリ容量がかなり厳しい機種も存在します。場合によっては計算性能ではなくメモリ容量の制限から必要なノード数を決定する必要があるケースもあるでしょう。
最後に、出力するデータ量についても計算して見積もりを示します。これは完全に問題に依存するため各自で計算する必要がありますが、「典型的な時間スケール毎に3次元の全データを出力」+「解析または動画作成用に2次元スライスデータや特定の変数のみを10倍以上細かく出力」のような組み合わせが典型的な設定だと考えられます。上の例で全データをファイルに出力する場合、単精度であれば保存量と磁場を出力する場合で(5+3)x643x4Bytes xプロセス数=25MBytes x プロセス数と見積もることができます。提供されているディスク容量で保存できるかどうかも重要ですが、それ以上に自分が解析しきれる量かどうか考えて出力するデータを検討する必要があります。
CPUもディスク容量も限りある共用の資源ですから、きちんと必要量を見積もった上で申請し、採択されたら責任をもって利用するようにしましょう。
課題
実際にAthena++を使用して、スケーラビリティを測定してみましょう。large-tキューを使えば120並列まで可能ですので、1(→2)→4(→8)→16(→20)→32→40→80→120並列で性能を測定してグラフを描いてみましょう。ウィークスケーリングでもストロングスケーリングでも構いません。(注:ノード当たり40コア未満で利用する場合は"aprun"コマンドに"-N"と"-S"オプションを付けないと性能が低下することがあります。)
他の(磁気)流体シミュレーションコードを持っている場合はそれと比較してみてください。また、Athena++でもRiemann Solverを変えたり精度を変えてPPMにしたりすると性能が変わります。自分のコードの性能を把握することはシミュレーション研究を設計する上で重要ですので、是非実践を通して学んでください。