コード開発に役立つ豆知識
ツールを使おう!
コードの開発は自分との戦いです。シミュレーションコードやコンパイラに問題があるケースもないわけではないですが、多くの、というかほぼ全ての場合自分で書いたコードに問題があります。私はプログラミング経験20年以上ありますが、コンパイラやライブラリのバグだったことは数回しかありません。人間というものは無意識に自分は正しいと信じているもので、その過信がバグの発見を妨げます。「そんな愚かな間違いはするはずがない」と(無意識であっても)思ってコードを読むと、容易にバグを見過ごします。デバッグというのは自身を謙虚に見つめ、基本に立ち返り己の愚かさと慢心を省みる、そんな精神修業的な作業でもあるのです。
数値シミュレーションの場合、計算の問題は(1)コンパイルが通らない (2)コンパイルは通るが計算がクラッシュ(不正終了)する (3)計算はクラッシュしないが結果が非物理的 (4)長時間計算すると問題が発生する・再現性がなくたまに失敗する・大規模並列計算の時だけ失敗するなど特定の条件下で失敗する (5)計算は正しいが性能が不十分 など様々なケースが存在します。このうち(1)は解決が容易で、コンパイラエラーを参考にしてコードを修正することになります。また(2)も比較的解決が容易で、クラッシュした場所を特定して修正することになります。(3)の場合、問題がコードの問題であるかそもそも物理または手法の問題であるかを特定する必要があります。例えば物理的に極めて不安定な系を解いていたり、マッハ数や磁場が非常に大きいなど数値シミュレーションの限界を超えた系を解いていたりする場合、コードが正しくても計算が破綻するケースがあります。この場合は手法や計算の設定をから再度検討する必要がありますが、一方コードに問題がある場合もその原因を特定するのはなかなか困難です。(4)はある意味最悪のケースで、何故・どこで問題が発生するのかという所から長いデバッグの旅が始まりますし、旅が始まるならまだしもそもそも気が付かないケースさえあり得ます。また(5)の場合、計算が正しくても有限の時間で必要な解が得られなければシミュレーションは十分役に立つとは言えません。これらの問題を解決するのはしばしば時間のかかる困難なものとなります。
「デバッグの基本は表示」とよく言われます。怪しい所の前後でとにかく関連する変数の内容を表示して、おかしな内容がないか確認してバグを探すというのはデバッグ基本的な作業です。小規模なコードであればこのような原始的な方法でもある程度は通用します。しかし、コードが大規模になると必ずしもそのような方法だけでは問題を特定することが難しくなってきますし、コンパイルの手間なども無視できなくなってきます。このようなデバッグの苦しみはあらゆるプログラマに共通のものであり、それを低減するための努力が当然行われていて、無料または有料で提供されているツールを有効に利用することでこれらの解決を劇的に容易にすることができます。ここではそのうち簡単なものを幾つかご紹介します。
デバッガ
コードがクラッシュしたのでその原因を特定したい、計算の途中で怪しい場所は大体わかったがそこでコードがどのように振る舞っているのかを詳細に調べたい、などの場合に役立つのがデバッガです。ここではLinux系のOSで標準的に用いられているgdbを使ってみましょう。gdbはGNUのツールですが、Intelコンパイラとも互換性があります。
デバッガを利用するにはコンパイル時にデバッグ情報を埋め込むようコンパイラに指示する必要があります。このためにはコンパイルオプションに-gを指定します。また、デバッグをする際は最適化による問題とコード自体の問題を切り分けるために最適化レベルを下げることが推奨されます。Athena++ではコードをconfigureする際に-dオプションを付けることでデバッグモードとなり、コンパイルオプションに-g -O0オプションを付加します。
> python configure.py --cxx icpc --prob blast -b -d
デバッガの使い方には二通りあります。一つ目は計算がクラッシュした際に出力される"core"ファイルを利用して、クラッシュした状況を解析する方法です。OSの設定によっては"core"ファイルが出力されないようになっていることがありますが、その場合はLinux系なら"ulimit -c unlimited"コマンドを実行することで"core"ファイルのサイズ制限を解除します。"core"ファイルを利用してデバッガを起動するためには以下のようにします。
> gdb ~/athena/bin/athena core
もう一つの起動方法はデバッガ内でコードを走らせてリアルタイムに必要な解析を行う方法です。この場合はまず実行ファイルを指定してgdbを起動したのち、runコマンドに必要なオプションを付加して計算を実行します。
> gdb ~/athena/bin/athena
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-80.el7
...
(gdb) run -i athinput.test
ここでは詳細な使い方を紹介することはできませんが、よく使うコマンドを以下に列挙しておきます。
- bまたはbreak [関数名等]: 指定した関数で実行を一時停止する(ブレークポイント)
- bまたはbreak [ファイル名]:[行番号]: 指定した場所で実行を一時停止する(ブレークポイント)
- lまたはlist: クラッシュした場所及び停止した場所付近のソースコードを表示する
- nまたはnext: その関数の次の行まで実行する
- sまたはstep: 次の行まで実行する。関数呼び出しがある場合はその関数の中で停止する
- pまたはprint [variable]: 変数の値を表示する。ポインタ・構造体内部も参照できる
- btまたはbacktrace: 関数の呼び出し元のグラフを表示する
- fまたはframe [num]: "bt"で得られた呼び出し元の関数に移動する
例えば以下の例ではblast.cppの初期条件の中のエネルギーを計算している117行目にブレークポイントを設定し、停止した付近のソースコードを表示したり、変数の中身をチェックしたり呼び出し元の関数を調べたりしています。
> gdb ~/athena/bin/athena
...
Reading symbols from /home/tomida/athena/bin/athena...done.
(gdb) b blast.cpp:117
Breakpoint 1 at 0x508474: file src/pgen/blast.cpp, line 117.
(gdb) r -i athinput.blast
Starting program: /home/tomida/athena/bin/athena -i athinput.blast
Breakpoint 1, MeshBlock::ProblemGenerator (this=0x74a960, pin=0x74a890) at src/pgen/blast.cpp:117
117 phydro->u(IEN,k,j,i) = pres/gm1;
(gdb) l
112 Real f = (rad-rin) / (rout-rin);
113 Real log_pres = (1.0-f) * std::log(prat*pa) + f * std::log(pa);
114 pres = std::exp(log_pres);
115 }
116 }
117 phydro->u(IEN,k,j,i) = pres/gm1;
118 if (RELATIVISTIC_DYNAMICS) // this should only ever be SR with this file
119 phydro->u(IEN,k,j,i) += den;
120 }
121 }}}
(gdb) p gm1
$1 = 0.66666666666700003
(gdb) bt
#0 MeshBlock::ProblemGenerator (this=0x74a960, pin=0x74a890) at src/pgen/blast.cpp:117
#1 0x00000000004a41f2 in Mesh::Initialize (this=0x74c1c0, res_flag=0, pin=0x74a890) at src/mesh/mesh.cpp:1221
#2 0x000000000040b874 in main (argc=3, argv=0x7fffffffd358) at src/main.cpp:285
(gdb) f 1
#1 0x00000000004a41f2 in Mesh::Initialize (this=0x74c1c0, res_flag=0, pin=0x74a890) at src/mesh/mesh.cpp:1221
1221 pmb->ProblemGenerator(pin);
(gdb) l
1216 bool iflag=true;
1217 do {
1218 if(res_flag==0) {
1219 pmb = pblock;
1220 while (pmb != NULL) {
1221 pmb->ProblemGenerator(pin);
1222 pmb->pbval->CheckBoundary();
1223 pmb=pmb->next;
1224 }
1225 }
(gdb)
詳細はgdbのマニュアルやgdb内で"help all"で表示されるヘルプメッセージを参照するなりWebで紹介しているサイトを検索するなりしてください。クラッシュした場所を特定してその時点での呼び出し元の情報や各変数の値をチェックするだけでも問題個所の特定する非常に強力なツールであり、問題解決に大いに役立ちます。
例として意図的にバグを仕込んだコードを用意しました。このコードは適当な問題で走らせると開始直後にクラッシュします。デバッガを使って原因個所を特定し、修正してください。
valgrind
プログラマを苦しめるよくある問題として「メモリリーク」という言葉を聞いたことがあるでしょうか。これはプログラム内でnewやmalloc等を使って確保したメモリを適切に開放しないまたは多重に確保するなど様々な原因により、アクセスできないメモリ領域を作り出してしまう問題です。短時間の計算であればプログラムの終了までこの問題が顕在化しない場合もありますが、長時間計算を実行したり多数回不適切なメモリの確保と解放を繰り返したりするとプログラムのメモリ領域が肥大化し、パフォーマンスの低下や最悪の場合メモリ不足による不正終了に至る場合があります。この問題はプログラムがすぐに不正に終了するわけではないので検出が難しく、埋もれたままになっていることも多々あります。valgrindはこのようなメモリリークをはじめ、メモリ関係の解析を強力にサポートしてくれる無料のツールの一つです。導入は簡単でaptやbrewでインストールすることができます。
valgrindでメモリリークを調査するにはまずコードを上述のデバッグモードでコンパイルしておきます。この時HDF5やMPIは誤検出の原因となるので外しておくことをお勧めします。その後コードをvalgrindの下で以下のように動作させます。valgrindはメモリ関係の操作を全て解析用のルーチンに置き換えて実行するため非常に時間がかかります。そのためこの調査をする際は計算規模を縮小し、数ステップだけ(nlim=1等をインプットファイルに指定する)実行すれば十分です。
> valgrind --leak-check=full ~/athena/bin/athena -i athinput.test
これで計算が実行され、メモリの二重確保や二重解放、ポインタの不適切な操作などメモリリークの原因を検出するとその情報が表示されます。さて、上の意図的にバグを仕込んだコードにはクラッシュするバグ以外にももう一箇所メモリリークを起こす問題を仕込んでありますが、通常の計算では一見正常に終了します。この例のメモリリークは致命的な問題には至らない比較的軽微なものですが、修正しておくに越したことはありません。valgrindを用いて問題点を特定して修正してください。
valgrindはここで使用したmemcheckというメモリを検査するツール以外に、メモリの使用量や配列のオーバーラン(範囲外へのアクセス)の調査、キャッシュの解析など多様なツールの集合体です。詳細は説明しませんが、例えばどこの関数でメモリを不必要に使用しているか、範囲外へのアクセスがデータを破壊していないか、などを調べるのにも役立ちます。デバッガと組み合わせて利用すればあなたのプログラミングの強力なサポートになるでしょう。
プロファイラ
コードが遅いという時、闇雲にコードを調べてもほぼ希望がありません。高速化・最適化を行うときにはまずどこで時間がかかっているかを特定する必要があります。このような場合に使用するのがプロファイラと呼ばれるプログラムで、gprofが代表的です。これを利用するためにはコードをコンパイルする前にMakefileを編集して-g -pgオプションを追加し(icでもgccでも共通です)、通常通り計算を実行します。計算が正常終了すればgmon.outというファイルが生成されます。
> vi Makefile ... CXX := g++ CPPFLAGS := CXXFLAGS := -O3 -g -pg LDFLAGS := LDLIBS :=
このファイルをgprofで処理すると計算時間の統計が表示されるので、どこで時間がかかっているのか特定することができます。実際にAthena++に対して実行した例を以下に示します。
> ~/athena/bin/athena -i athinput.test > gprof ~/athena/bin/athena gmon.out > gprof.out > less gprof.out
Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 45.73 6.43 6.43 600 10.72 10.72 Hydro::RiemannSolver(int, int, int, int, int, int, int, AthenaArray<double> 8.75 7.66 1.23 200 6.15 43.88 Hydro::CalculateFluxes(AthenaArray<double>&, FaceField&, 5.69 8.46 0.80 200 4.00 4.32 Hydro::AddFluxDivergenceToAverage(AthenaArray<double>&, 5.05 9.17 0.71 200 3.55 3.55 Field::ComputeCornerE(AthenaArray<double>&, AthenaArray<double>&) 4.20 9.76 0.59 500 1.18 1.18 Field::WeightedAveB(FaceField&, FaceField&, FaceField&, double const*) 3.34 10.23 0.47 __intel_avx_rep_memcpy 3.27 10.69 0.46 200 2.30 6.62 TimeIntegratorTaskList::HydroIntegrate(MeshBlock*, int) 2.99 11.11 0.42 101 4.16 4.19 Hydro::NewBlockTimeStep() 2.92 11.52 0.41 201 2.04 2.99 EquationOfState::ConservedToPrimitive(AthenaArray<double>&, 2.92 11.93 0.41 701 0.58 0.58 Reconstruction::PiecewiseLinearUniformX3(Coordinates*, int, int, int, int, int, 2.84 12.33 0.40 700 0.57 0.57 Reconstruction::PiecewiseLinearUniformX1(Coordinates*, int, int, int, int, int,
この例ではRiemannSolver(HLLD)が計算時間の大部分(計算時間のおよそ半分近く)を占めているということが明らかになります。最適化をする場合はまずここから取り組むことになるでしょう。さらにファイルの下の方に行くと、関数間の呼び出しの関係などについての情報も表示されます。
コードを最適化する場合は時間のかかっている場所の方が大きな効果が期待できますから、時間のかかっている場所から順に取り組むべきです。逆に時間がかかっていいない所は多少最適化が甘くても全体に与える影響はほとんどないので、費用対効果を考えて最適化を行いましょう。
Intel Advisor
商用のツール(→無償で利用できるようになりました!)ですので詳しくは紹介しませんが、Athena++の最適化に我々が活用しているツールにIntel Advisorがあります。これはIntel OneAPI Toolkit(Intel コンパイラ)に含まれているツールで、コードの性能を測定して理論的に達成されるべき限界のどれくらいまで達しているかをサブルーチン・ループ毎に解析するだけでなく、その性能を改善するために取り得る最適化手法の提案までしてくれる非常に強力なツールです。使い方も簡単で-gオプションを付けてビルドしたコードをGUI上で実行するだけで、次のようなグラフで表示してくれます。以下の図では各サブルーチンが色付きの点が示されており赤→黄→緑の順に計算時間に占める割合が大きいものを表しています。ここではHLLDリーマンソルバが一番大きな割合を占めているので赤丸で示されています。それに対して理論的な性能限界が点線で示されており、HLLDについてはL3キャッシュのバンド幅を超える性能が出ていますので比較的よく最適化ができているといって良いでしょう。コード・手法にもよりますが、一般にキャッシュのバンド幅を最大限に利用することはそう容易ではないので、メモリ(DRAM)バンド幅を超えていればそう悪くないと考えて良いと思われます。一方以下では黄色のPLMリコンストラクションはやや最適化の余地がある可能性を示しています。
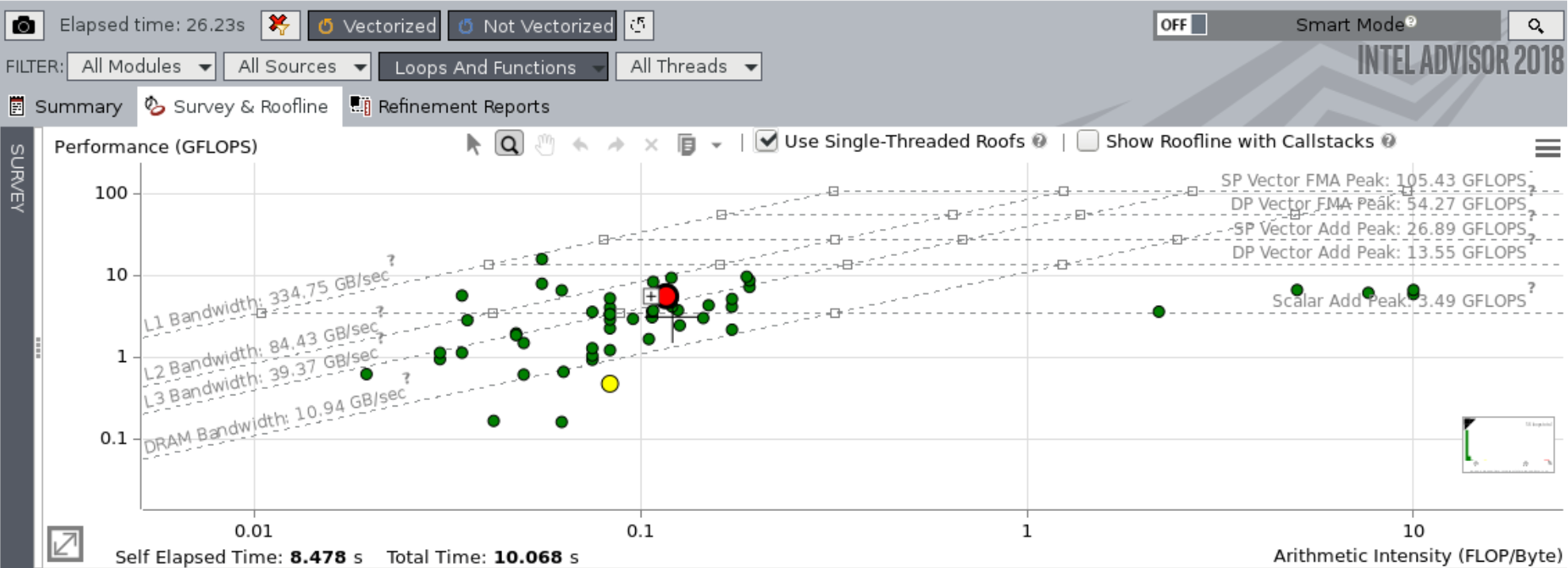
大変強力なツールで見ているだけでも楽しいので、御自身のコードの最適化に是非試してみることをお勧めします。
その他のツール
その他にもパフォーマンスの向上やデバッグのためのツールは多数提供されています。特にMPIを用いた大規模並列計算のデバッグ及び最適化は多くのプログラマを悩ませているものですが、これにもTotalViewやDDTなどの商用ツールが良く使われています。本講習会ではこれ以上立ち入りませんが、各計算センターでサポートされている場合がありますので興味があれば問い合わせてみると良いと思います。
MPIの裏側
MPI(Message Passing Interface)はプロセス間通信の事実上の業界標準であり、今日スーパーコンピュータを利用するには必須の技術と言えます。MPIはその名の通りプロセス間で通信メッセージをやり取りしてデータの送受信を行う仕組みですが、その動作の仕組みは興味深く、あなたの計算の裏でMPIがどのように動作しているのかを知ることは高い性能を実現するのに役立つかもしれません。ここでは少しその裏側が垣間見られる事例を紹介したいと思います。ただし、MPIが仕様として定義しているのはその名の通りinterfaceであり、一定の要求を満たすならば内部的な実装についてMPIは何ら要請していません。そのため、ここでの話は必ずしも全てのMPI実装に当てはまるものではないことをお断りしておきます。
MPIで多数の通信を並行して行うためにはノンブロッキング通信と呼ばれる手法を用います。これはMPI_Isend/Irecvなどの関数に代表されるもので、これらの関数を用いて通信の開始を指示した後はMPI_Waitを用いて通信の終了を待つか、MPI_Testを用いて通信の終了を確認することになります。この振る舞いをユーザーから見れば、単純には「MPIはバッググラウンドで動作して自動的に通信を行っている」と解釈するのではないでしょうか。確かにネットワークカードはCPUとは独立に動作しますから、これは部分的には正しいと言えます。しかし一方で通信にはメモリ上のデータをネットワークカードに転送する、あるいはその逆などCPUとメモリが介入する処理が必要です。さて、MPIはこの部分もバックグラウンドで自動的にやってくれて、MPI_WaitやMPI_Testを実行しなくとも一定時間が経てばメモリ上にデータが転送されるのでしょうか?確かにそのような実装も存在します(具体例として富岳ではそのようなMPIが採用されています)が、スーパーコンピュータでは勝手にスレッドを起動するとパフォーマンスに悪影響がある恐れがあり、起動できるスレッド数にも制限がある場合があるため、多くのMPIではそのような実装にはなっていません。
ではMPIがどのように通信を行うのかというと、実はMPIはMPIに関係する関数が実行される際に必要な処理をこっそり行うことで疑似的にバックグラウンドで動作しているように見せかけています。そのため、MPIの関数を呼ばないと必要な処理を行う機会が十分に与えられず通信が進行しないということが起こり得ます。逆に言うと、MPIの関数を適宜呼ぶことでMPIに必要な処理を行う機会を与え、効率よく通信を処理できるようになることがあります。実際にこのためにAthena++ではMPI_Iprobeを境界通信処理の中で実行しています。この関数は指定した条件に合う通信が存在するかどうかをチェックするだけで、コード内ではその結果を使用していないので一見無駄なことをしているように見えるかもしれませんが、この関数を挿入することで実際に大幅にパフォーマンスが改善しました。皆さんのコードでも試してみると効果があるかもしれません。
#pragma omp simd
近年の計算機で性能を出すためには、複数のメモリ上連続した変数に対して一括して演算を行うSIMD化またはベクトル化と呼ばれる機能を最大限に使うことが必須となっています。OpenMP4.0以上をサポートする最近のコンパイラでは、ループの(コンパイラによってその程度は異なるものの)ベクトル化を指示する#pragma omp simdと呼ばれる指示文がサポートされています。これは計算に関する依存性を無視するために結果の正確さは保証されませんが、ベクトル化して問題がないという確信が持てる場合には極めて強力な最適化の手段です。Intel Advisorと組み合わせると最適化の可否を判定することができ、コードの性能を大幅に向上できる可能性がありますので、ぜひ試してみることをお勧めします。